Este año también me fui de vacaciones con la intención de volver con ideas para promover algún tipo de acción pidiendo una revisión de los currículos de matemáticas. Y supongo que, como en años anteriores, la intención se habría quedado en eso, sepultada por el resto de tareas que uno se encuentra de cara al comienzo de curso, de no haber sido por este tuit de hace unos días:
Conclusión PISA: dar menos conceptos pero con más profundidad y relacionar e interconectar distintas ideas entre sí pic.twitter.com/QRHANXeGTu
La imagen del tuit es la transparencia 54 del powerpoint de este informe, que me parece interesante en general.
Creo que la gran mayoría de los profesores estamos de acuerdo en que los currículos son demasiado extensos. De hecho, este problema ha empeorado con la LOMCE. Si los informes de organizaciones a las que se recurre tan a menudo cuando se habla de competencia matemática coinciden en que es mejor elegir menos contenidos, para poder tratarlos en profundidad, ¿no debería este tema llegar al debate social? Seguramente las asociaciones de profesores podrían ser la opción natural, pero mis (escasos) intentos en el pasado reciente han tenido resultado cero. Creo que ha llegado el momento de intentar sacar partido de las nuevas tecnologías, y ensayar la participación directa. El objetivo de esta entrada es (aparte de tratar de forzarme a dar el paso) pedir opinión a los lectores, y recabar ideas. ¿Conocéis alguna alternativa que pudiera ser más adecuada que Change.org?
Lo que me parecía imposible hace un año ha resultado no serlo tanto: este fin de curso ha sido todavía más ajetreado que el anterior. No es una queja, porque la mayoría de las tareas son estrictamente voluntarias, y estoy muy contento de cómo van. Algún viaje profesional, las evaluaciones de mis alumnos, el trabajo con los libros de Singapur que llegan a los coles el próximo septiembre y, como guinda, el trabajo en la organización de la IX Escuela Miguel de Guzmán. El objetivo de esta entrada es pasar a limpio mis conclusiones sobre estas jornadas, y que además esto sirva como cierre del curso.
Lo primero, tal y como me comprometí durante la Escuela, aquí están enlazados los materiales que varios de los ponentes y encargados de los talleres ponen a disposición de la comunidad. ¡Gracias!
Para empezar por el final, la sensación que me quedó al terminar la Escuela fue, como otras veces en estos casos, agridulce. Para ser justos, dulce, pero con un pequeño toque agrio. Por supuesto, fueron días llenos de debates interesantes, intercambio de ideas y propuestas, y muy formativos. El toque agrio viene de la sensación de que estábamos reunidos una parte de la comunidad docente que estamos de acuerdo en muchas cosas, pero quizá olvidando que sigue habiendo una mayoría a la que no llegan estos mensajes. Es verdad que hubo algunas intervenciones en los debates de participantes que manifestaron que participaban en este tipo de eventos por primera vez, que le habían interesado mucho, y que volvían a casa con muchas cosas sobre las que pensar. En resumen: objetivo cumplido, y un detalle en el que creo que podríamos mejorar, tratar de llegar a una parte mayor de la profesión.
Lo que quiero hacer en el resto de esta entrada es dejar por escrito algunos comentarios sobre las ponencias, incluyendo también alguna observación crítica, cuando toque.
Clara Grima, en la conferencia inaugural, nos demostró que se pueden decir cosas muy interesantes, y ser divertida, a la vez. No es algo que se vea con excesiva frecuencia en nuestro mundo …
Cecilia Calvo nos habló de las tareas ricas: su observación fundamental es que hay habilidades básicas que hay que practicar, pero que muchas veces esa práctica se puede hacer a través de esas tareas ricas, donde además hay involucradas actividades con valor cognitivo. En su presentación hay varios ejemplos, y en el espacio Puntmat muchos más. Me parece una propuesta muy interesante, con una sola debilidad: creo que para llevar esto al aula se necesitan docentes muy bien formados.
Juan Francisco Hernández, del Hispano-Inglés de Santa Cruz de Tenerife, nos habló de la clase invertida. Creo que merece la pena echar un vistazo a los materiales que ha puesto a nuestra disposición. No voy a entrar en el debate de fondo sobre la clase invertida, pero sí quiero mencionar que cuando se piensa en una metodología habría que tener en cuenta que una cosa es funcionar bien, o muy bien, con un docente – o un equipo docente – determinado (formado, trabajador, etc), y en un centro determinado, y otra cosa es que esa metodología sea generalizable al sistema escolar. Recomiendo estas reflexiones de El Lolaberinto sobre el tema.
Irene Ferrando habló sobre modelización. En su presentación (15 Mb) hay varios ejemplos muy interesantes. Por otra parte, aquí se aplica la misma observación del párrafo anterior, sobre metodologías «exportables», y un comentario adicional: en un vídeo donde nos enseñaba un proyecto de estimación de la cantidad de papel de aluminio en un colegio (el proyecto me pareció muy interesante) vimos a un alumno con la famosa «escalera de las unidades», subiendo peldaños y añadiendo ceros (¿o quitándolos?, nunca lo recuerdo). Los proyectos, la modelización, o la clase invertida, pueden ser buenas herramientas para motivar a nuestros alumnos (y esto es un valor en sí mismo, lo sé), pero creo que si no cambiamos algunas cosas de fondo, los resultados sobre el aprendizaje real serán limitados.
Para terminar, Lurdes Figueiral, la presidenta de la asociación de profesores de matemáticas de Portugal, nos presentó el currículo producto de la reforma de 2011. No recuerdo haber oído nada al respecto (sí, me temo que soy uno más de esa mayoría social que hace bien poco caso a lo que ocurre en nuestro vecino del oeste), pero parece que fue una reforma curricular bastante polémica, hecha en contra de la profesión. La impresión que trasladó Lurdes Figueiral fue muy negativa. Aquí está el currículo. El aspecto no es bueno, desde luego. Un interminable listado de contenidos … Una cosa, al menos, me gusta: los autores dan la cara, en primera página. La reforma se hizo bajo el mandato de un ministro de educación con formación de economista-matemático, Nuno Crato.
No asistí a ningún taller, fueron los ratos que dediqué a las gestiones organizativas, pero todos los comentarios que escuché fueron positivos.
En cuanto a las mesas redondas, al final las dos giraron en torno al tema de en qué debería consistir el aprendizaje matemático elemental (para mí, entendido como el correspondiente a la educación obligatoria) en estos tiempos. En la mesa de las calculadoras, Juan Emilio García nos mostró un par de vídeos que provocaron los momentos más hilarantes de la Escuela. Parece ser que los vídeos ya estaban en youtube. Yo no los conocía, y los quiero compartir aquí, porque además de divertidos me parece que tienen su interés didáctico.
El primero es una muestra perfecta de por qué hay que dedicarle algo de atención a enseñar a usar las calculadoras:
En el segundo, tres de las estrellas del humor español de los 70, con los cambios de unidades, y nuestra querida regla de tres …
Para terminar, como le dediqué cierto tiempo a pensar sobre mi intervención en la mesa redonda «Las matemáticas en la educación obligatoria del Siglo XXI», pensé que sería buena idea guardar esas reflexiones de alguna forma. En lugar de escribirlas, lo que he hecho es preparar un vídeo, porque me ha servido además de primera práctica con la herramienta ActivePresenter. Su versión gratuita me ha parecido bastante potente, y sencilla de empezar a usar.
Sirva este vídeo (20 min) de despedida por este curso. ¡Feliz verano a todos los lectores!
Lo único que había visto hasta ahora de Shanghai era sus excelentes resultados en las pruebas de siempre. No parece que sea sencillo conseguir información. No he encontrado su currículo en inglés, y los textos que usan allí tampoco están en inglés. Parece que este tema ha surgido por el proyecto de implantar estas metodologías en colegios (de primaria) de Gran Bretaña. Aquí hay algo de información sobre Shanghai, y algunos materiales de muestra (de los primeros cursos de primaria).
En este otro enlace de Maths no Problem se puede leer una comparativa sobre Singapur y Shanghai. Creo que debo avisar de que es una comparativa interesada: Maths no Problem es la editorial británica que empezó a trabajar con Marshall Cavendish, la editorial más importante de Singapur. Recientemente Marshall Cavendish se ha aliado con Oxford University Press (aquí) y creo que Maths no Problem está trabajando con otra editorial de Singapur. En cualquier caso (y aunque mi opinión también puede estar sesgada, desde luego), creo que tienen bastante razón en lo que dicen. La fortaleza esencial de Shanghai puede ser la excelente preparación de su profesorado, mientras que la metodología de Singapur puede depender menos de la excelencia del docente (eso no quiere decir que lo ideal no sea tener buenos docentes, claro, en este espacio no creo que haya que hablar de una función de varias variables).
Lo que sí es cierto sobre Singapur, y esto lo he repetido muchas veces en las últimas semanas, presentando los libros de Polygon Education en los colegios de la zona de Madrid, es que la metodología de Singapur se hizo famosa, a nivel internacional, por su éxito en el movimiento homeschooling de EEUU. ¿La razón? Creo que sencilla: los padres descubrieron que «esas matemáticas» sí las entendían. Y también es cierto que en Singapur eligieron la metodología teniendo bien presente que sus docentes de hace 30 años tenían una formación más bien tirando a básica. Las cosas han cambiado, desde luego (por ejemplo, los profes de Singapur tienen 100 horas de formación continua obligatoria al año. Vamos, 6 veces más que aquí en cantidad. Y apuesto a que en calidad también nos aventajan) pero creo que algo de esa idea de «facilidad de presentación» todavía subsiste.
Termino con una especulación: el lector atento se puede haber dado cuenta de que detrás de los materiales de Shanghai que enlacé arriba está Collins, otra de las grandes editoriales británicas. Es posible que la razón de que aparezca Shanghai sea simplemente que es la forma que Collins ha encontrado de unirse al movimiento de renovación en Gran Bretaña, porque allí el gobierno ha puesto mucho dinero en este tema.
Somos el país de la taxonomía, nos encanta dar nombres, clasificar, y luego poder pedir a nuestros alumnos que memoricen todo lo que se nos ocurra. Resulta simplemente kafkiano que, en un descanso de una lectura de un Trabajo Fin de Grado, en el que compruebas una vez más que muchos de nuestros graduados tienen serios problemas para expresarse con una mínima corrección, puedas escuchar a tu hija, que cursa 1º de Bachillerato, que está estudiando un examen de lengua, y está repasando los sustantivos hipónimos e hiperónimos.
Simplemente, estamos locos.
Hoy una entrada breve para anunciar la IX Escuela de Educación Matemática Miguel de Guzmán, organizada de forma conjunta por la Federación Española de Sociedades de Profesores de Matemáticas y la Real Sociedad Matemática Española.
Será los días 6-7-8 de julio, en la Universidad de Alcalá. El título de la Escuela es «Qué enseñar y cómo hacerlo: nuevas metodologías», y aunque me gustaría que el programa tuviera más espacio para discutir el «qué», antes de pasar al «cómo», algo hay en esa dirección, y espero que la participación del profesorado ayude. El plazo de inscripción es del 2 de mayo al 20 de junio.
Me parece una expresión muy adecuada para presentar la idea detrás del Teorema de Bayes: si un cierto test médico ha dado positivo, hay dos posibles causas, que la persona esté enferma, o que se trate de un falso positivo. ¿Cómo de probable es cada una de ellas? Esa es justamente la pregunta que contesta la conocida fórmula:
Seguro que la mayoría de los lectores la conocen, es el resultado final del tema estándar de probabilidad elemental, y parte del temario de las matemáticas de bachillerato. Pero si algún lector no la conoce, que siga leyendo, por favor. Parte de esta entrada estará dedicada al significado de la fórmula de Bayes.
Pero antes, quería dedicarle un párrafo al libro en el que he descubierto la expresión «La probabilidad de las causas» para presentar la fórmula de Bayes. Es un texto escrito por dos compañeros de mi departamento. Aunque está pensado para un curso de Estadística de 1º de un Grado en el área de Ciencias/Ciencias de la Salud, creo que puede ser útil en Bachillerato, y en general para cualquiera que quiera entender las ideas de fondo de la Estadística. Porque lo que me ha resultado más atractivo del libro es su empeño (casi siempre coronado por el éxito) en transmitir las ideas de fondo tras las técnicas básicas de la Estadística. Es posible que me haya resultado tan interesante precisamente porque ha permitido que entienda algunas de las cosas que siempre me habían resultado escurridizas. El libro está accesible online y además está acompañado de una parte práctica que incluye una introducción a R.
Veamos ahora un ejemplo estándar de aplicación del Teorema de Bayes a un test de diagnóstico. Supongamos que cierta enfermedad afecta al 0,5 % de la población, y que tenemos una prueba para detectarla. Ninguna prueba es completamente fiable, y hay dos tipos de errores. Los falsos positivos son los casos en los que la prueba da positivo aunque la persona no está enferma, y los falsos negativos son los casos en los que la prueba da negativa aunque la persona está enferma. Es fácil imaginar que en la práctica existe una relación entre estos dos tipos de errores, y que para hacer muy pequeña la cantidad de falsos negativos necesitaremos pruebas muy sensibles, que tendrán, en general, una tasa mayor de falsos positivos. Compensar adecuadamente estos dos parámetros es uno de los problemas centrales del diseño de pruebas médicas, ya que el equilibrio deseable varía en cada situación. En nuestro ejemplo, y para simplificar, supondremos que no hay falsos negativos, y que los falsos positivos son el 5 %.
Supongamos ahora que elegimos una persona al azar, le hacemos la prueba y el resultado es positivo. ¿Qué probabilidad hay de que esté enferma? Si llamamos E al suceso «persona enferma», y + al suceso «resultado de la prueba positivo», en el lenguaje de la probabilidad condicionada la probabilidad que queremos calcular es P(E|+). Según la fórmula de Bayes,
Es decir, en términos de porcentajes, la probabilidad de que la persona esté enferma es aproximadamente el 9,09 %. No despreciable, desde luego. El resultado positivo de la prueba la ha multiplicado casi por 20, pero seguramente es más baja de lo que los lectores sin experiencia en este tema esperaban.
Creo que la forma más sencilla de entender este resultado (y de entender la fórmula de Bayes), es pensarlo en términos de fracciones. El rectángulo de la figura representa el total de la población, el rectángulo rojo de la esquina superior izquierda las personas enfermas, y el rectángulo rojo de la esquina inferior derecha los falsos positivos. El modelo está hecho a escala, de forma que las áreas relativas representan las probabilidades. En este modelo, la pregunta anterior – el resultado de la prueba en una persona elegida al azar es positivo, ¿cuál es la probabilidad de que esté enferma? – se convierte en: elegimos un punto rojo al azar (un resultado positivo). ¿Cuál es la probabilidad de que sea un punto de la esquina superior izquierda? Como el área total de los puntos rojos (como fracción del total) es 0,005 + 0,05 y el área de la esquina superior izquierda es 0,005, vemos que la probabilidad es, en efecto, 0,0909.
En un comentario de la última entrada Lucas preguntaba por el programa de Jesús Cintora sobre los deberes, en particular sobre la intervención de Alberto Royo, autor de «Contra la nueva educación» (autor y libro que yo descubrí en el programa).
Mi conclusión principal sobre el programa es que es frustrante el poco rigor y la poca profundidad que hay en nuestro debate público. Como ya han pasado unos días, si algún lector quiere refrescar la memoria el programa está aquí y la intervención de Alberto Royo empieza en el minuto 23:30. Creo que merece la pena complementar esos minutos con esta entrada de su blog,
En este debate siempre he echado de menos los números. Ya en las lejanas reuniones del cole de mis hijas, lo único que intentaba cuando surgía el inevitable debate entre los bandos de padres pro y anti deberes era poner algún número a la cantidad de deberes. Nunca lo conseguí, los maestros solían salirse por la tangente de «cada niño es distinto». ¡Pues claro que cada niño es distinto! Por eso no tiene sentido mandarles a todos las mismas tareas, al que las necesita y al que no, al que se concentra y las hace en media hora y al que todavía se distrae mucho, y necesita media tarde para ello.
José Antonio Marina (minuto 49) sí se atrevió a poner un número: 15 minutos al día en 1º y subiendo 15 minutos cada curso. Me parece que llegar a 1,5 horas al final de primara es demasiado, pero al menos con estas cifras se podría empezar a hablar.
Como prueba de la superficialidad del programa me quedo con la situación de la estudiante de ESO (1h 02 min), y el relato de sus tareas del día: «pasar a limpio» una redacción de inglés y estudiar para el examen, estudiar los resúmenes de sociales y un ejercicio de matemáticas. Es verdad que «estudiar para un examen» es una tarea con duración difícil de valorar, y lo mismo estudiar los resúmenes, pero su madre en el programa dice que es una chica eficiente y que los hace en 1 hora. Mi reacción fue: ¿cómo es posible entonces que esté haciendo deberes a las 21:30? ¿No haría falta dar algo más de información sobre el horario de la estudiante durante esa tarde?
En fin, que el propósito fundamental de esta entrada era dar entrada al debate de los lectores que os animéis.
Muchas gracias a todos por las aportaciones. Creo que ha habido tres soluciones distintas, y que tiene sentido recapitularlas.
Con probabilidad elemental, fijando un primer equipo español, digamos el A. La probabilidad de que su rival sea español es . Que el rival de A no sea español tiene probabilidad , y en ese caso que el rival de B sea el tercer equipo español tiene probabilidad . Por tanto, la probabilidad de eliminatoria española era .
Directamente con la regla de Laplace, contando casos favorables y posibles. En algún momento hablaremos de la combinatoria, casi desaparecida del currículo. Y cuando se trata, reducida a variaciones, permutaciones y combinaciones, con sus correspondientes fórmulas. A la hora de la verdad, muchas cosas no son nada de eso. Por ejemplo, los posibles emparejamientos entre n equipos.
Para la primera eliminatoria hay posibilidades, para la segunda , etc. Como es mejor ignorar el orden de esos emparejamientos, tras dividir por se obtiene la fórmula para el número de emparejamientos entre n equipos: . Tras simplificar queda (como observó ricardito) que el número de emparejamientos entre n equipos es el producto de los impares menores que n. En el caso de los 8 equipos, .
¿En cuántos de ellos hay eliminatoria española? Hay 3 posibles emparejamientos entre equipos españoles, y para cada uno de ellos hay que emparejar los restantes 6 equipos. Por tanto, hay emparejamientos con eliminatoria española.
Para terminar, mi modelo de las bolas rojas. Consideramos 8 posiciones, distribuidas en 4 cajas. La posición 1 y 2 en la primera caja, la 3 y la 4 en la segunda, etc. Hay formas de colocar 3 bolas en esas 8 posiciones. Si en una caja hay dos bolas, hay 6 huecos para la bola roja restante. Por tanto, en de las distribuciones de bolas hay 2 en la misma caja, y la probabilidad es .
Actualización 3: un lector pregunta por los detalles del sorteo. Creo que lo razonable es aclarar eso al principio. Se trata de un sorteo puro, cualquier combinación es igualmente probable. Los detalles de cómo se lleva a cabo el sorteo «real» son irrelevantes, eso es parte del tema de «elegir bien el modelo», sobre el que quería escribir en esta entrada. En todo caso, simplemente hay 8 bolas en un bombo, y se van extrayendo una a una. Se empareja 1ª con 2ª, 3ª con 4ª, etc.
Tal y como ha quedado la entrada, creo que también es justo avisar a los lectores de que el reto es encontrar el fallo en los dos primeros argumentos.
———————————————————
A cuenta del sorteo de la Champions, en el que de un total de 8 equipos tenemos 3 españoles, @edusadeci lanzó la pregunta de qué probabilidad hay de que el sorteo empareje a dos equipos españoles, ya advirtiendo de que no es un problema tan sencillo como parece. Merece la pena echar un vistazo a las respuestas, realmente variadas …
Creo que es un ejemplo más de lo difícil que es la probabilidad, y de que muy pronto aparecen preguntas «sencillas» nada fáciles de contestar.
El aspecto que más me interesa del problema es que es un ejemplo perfecto de la importancia de elegir un buen modelo. Desde luego, la probabilidad se puede calcular directamente contando resultados del sorteo. Pero no es sencillo, y es otro buen ejemplo de lo sutil que es la combinatoria, sobre todo dado lo desentrenados que estamos en ella (su presencia en la educación matemática obligatoria es menos que testimonial).
El modelo que me parece más sencillo para contestar la pregunta original es considerar 4 cestos, y 3 bolas rojas. Si colocamos al azar las 3 bolas en los cestos, ¿cuál es la probabilidad de que caigan en cestos distintos? La clave para darse cuenta de que es el mismo problema es considerar las 8 bolas del sorteo, y ver el sorteo como el procedimiento de extraer bolas, al azar, e irlas colocando de dos en dos en los cestos. Podemos imaginar las bolas de los equipos españoles coloreadas de rojo, y darnos cuenta de que realmente el resto de las bolas ¡no juegan ningún papel! Visto así, queda también claro que se trata de una variante del problema del cumpleaños, donde tenemos 3 personas, que cumplen años en 4 días (con probabilidad uniforme, e independientes, claro) y nos preguntamos por la probabilidad de que sus cumpleaños sean distintos.
Una vez hemos llegado aquí, el resto es probabilidad «sencilla». Si numeramos las 3 bolas según el orden en que las colocamos en los cestos y consideramos los sucesos
«la bola cae en un cesto vacío» (para )
vemos que calcular la probabilidad de que no haya eliminatoria entre dos equipos españoles es una pregunta que se puede responder con conocimientos básicos de probabilidad condicionada:
Actualización: podría decir aquello de «estaba preparado para ver si alguien prestaba atención», pero en absoluto, mi argumento está mal, sin paliativos. Un fiel seguidor del blog me lo ha hecho ver: el problema del modelo que propongo es que no excluye que haya tres bolas en un cesto, cosa prohibida en el sorteo. Eso sí, la solución que propone el lector (matemático, como yo) creo que tampoco es correcta. Al final, esta entrada va a ser sobre todo una prueba de que, con la probabilidad y la combinatoria, cualquiera puede cometer errores. Y que modelar de forma correcta es complicado, aún en situaciones «sencillas».
Como ya no me fío de nada he decidido recurrir a la «fuerza bruta», y contar las formas de colocar 3 bolas rojas en 4 cestos, sin permitir que haya 3 en el mismo. Son 16, y aquí están:
De esas 16, sólo en 4 se evita el emparejamiento entre dos equipos españoles. Por tanto, la probabilidad de que haya una eliminatoria española es 3/4. Nada extraño que haya ocurrido …
Actualización 2: nuevo error, otra vez de principiante. Los sucesos de la figura NO son equiprobables. Si pensamos en las permutaciones de 8 elementos, que sí son equiprobables, y vemos el sorteo como emparejar 1 y 2, 3 y 4, etc, los sucesos con 3 bolas en distintos cestos se pueden completar a 8 permutaciones (en el sentido de contar sólo las posiciones de las bolas rojas), mientras que los que tienen dos bolas en un mismo cesto se pueden completar solo a 2. Visto así, el conteo para los sorteos sin emparejamiento español es 32/(32+56) = 4/7, que sí coincide con la solución que proponía Roberto Muñoz, el lector que me hizo ver mi primer error.
Lo dicho, la probabilidad es resbaladiza, y si algún lector tiene un futbolín y cree que debo pasar por debajo de él, estoy dispuesto.
El pasado sábado hubo una interesante conversación en twitter alrededor del máximo común divisor y los algoritmos para calcularlo. @druizaguilera proponía este diagrama conjuntista para determinar los factores comunes:
Estos días he seguido dándole vueltas al tema, y han cristalizado algunas ideas sobre las que llevaba tiempo pensando.
El primer comentario es que los métodos propuestos son realmente algoritmos para calcular intersecciones de multiconjuntos, y mi gran pega es que enseñan muy poco sobre qué es el máximo común divisor. Mi impresión es que la mayor dificultad de este tema no es el cálculo, sino la comprensión del concepto, para poder aplicarlo en la resolución de problemas. Del vídeo que enlacé en su día sobre lo que hacían mal en Singapur en los años 70, me interesa cada vez más una de las cosas que se mencionan: los procedimientos y la comprensión conceptual hay que trabajarlos en paralelo (el vídeo dura 5 min, y este tema se empieza a tratar a los 40 seg):
Para trabajar en paralelo la comprensión y el cálculo del mcd (y del mcm) me parece más interesantes las actividades que proponen Cecilia Calvo y David Barba en su trabajo publicado en SUMA, y que los autores han puesto aquí (vía @druizaguilera).
El tema del máximo común divisor y el mínimo común múltiplo lo trato en magisterio, a todos los alumnos les suena la receta de «factores comunes …», y lo hacen bien, en general, sin necesidad de procedimientos ad hoc. Lo que me sorprende es que ninguno parece estar familiarizado con el hecho de que a partir de la factorización de un entero es fácil escribir el conjunto de sus divisores, lo cual es tanto como decir que no tienen idea de por qué funciona la receta que usan para calcular el máximo común divisor. Creo que es un tema sencillo de entender, no hay más que pararse a comparar el conjunto de divisores de un número como 36 con su factorización. La relación entre factorización y divisores da mucho juego (estos temas han sido para mí un descubrimiento reciente, a raíz de impartir clases en magisterio: la aritmética elemental está llena de relaciones que dan lugar a auténtico pensamiento matemático). Por ejemplo, a partir de la relación entre factorización y divisores se pueden contar el número de divisores de un entero: si (p, q y r son números primos distintos, claro), entonces n tiene 24 divisores. A la inversa (examinar un problema al revés es una de las mejores formas de profundizar en su comprensión), puedo construir números con, por ejemplo, 18 divisores, de estas formas: , $p^5\cdot q^2$, . ¿Cuál es el número más pequeño que tiene 18 divisores?
Hay otro aspecto quizá incluso más importante. Los pedagogos dicen (y en este punto estoy de acuerdo con ellos) que algo se ha aprendido de verdad cuando el conocimiento se puede transferir a otra situación. Y aquí radica la extraordinaria potencia del método matemático: que las ideas y las estrategias que involucra son transferibles a una cantidad sencillamente sorprendente de situaciones. Cuanto más especializado sea un procedimiento, menos transferible será. No dudo de que las propuestas del principio de esta entrada sean útiles para que los alumnos hagan los cálculos necesarios para superar el examen correspondiente, lo que dudo es qué quedará de todo eso un año después de haber hecho ese examen.



 . Que el rival de A no sea español tiene probabilidad
. Que el rival de A no sea español tiene probabilidad  , y en ese caso que el rival de B sea el tercer equipo español tiene probabilidad
, y en ese caso que el rival de B sea el tercer equipo español tiene probabilidad 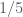 . Por tanto, la probabilidad de eliminatoria española era
. Por tanto, la probabilidad de eliminatoria española era  .
. posibilidades, para la segunda
posibilidades, para la segunda 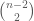 , etc. Como es mejor ignorar el orden de esos emparejamientos, tras dividir por
, etc. Como es mejor ignorar el orden de esos emparejamientos, tras dividir por  se obtiene la fórmula para el número de emparejamientos entre n equipos:
se obtiene la fórmula para el número de emparejamientos entre n equipos:  . Tras simplificar queda (como observó ricardito) que el número de emparejamientos entre n equipos es el producto de los impares menores que n. En el caso de los 8 equipos,
. Tras simplificar queda (como observó ricardito) que el número de emparejamientos entre n equipos es el producto de los impares menores que n. En el caso de los 8 equipos,  .
. emparejamientos con eliminatoria española.
emparejamientos con eliminatoria española. formas de colocar 3 bolas en esas 8 posiciones. Si en una caja hay dos bolas, hay 6 huecos para la bola roja restante. Por tanto, en
formas de colocar 3 bolas en esas 8 posiciones. Si en una caja hay dos bolas, hay 6 huecos para la bola roja restante. Por tanto, en  de las distribuciones de bolas hay 2 en la misma caja, y la probabilidad es
de las distribuciones de bolas hay 2 en la misma caja, y la probabilidad es  .
. «la bola
«la bola 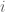 cae en un cesto vacío» (para
cae en un cesto vacío» (para 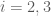 )
)



 (p, q y r son números primos distintos, claro), entonces n tiene 24 divisores. A la inversa (examinar un problema al revés es una de las mejores formas de profundizar en su comprensión), puedo construir números con, por ejemplo, 18 divisores, de estas formas:
(p, q y r son números primos distintos, claro), entonces n tiene 24 divisores. A la inversa (examinar un problema al revés es una de las mejores formas de profundizar en su comprensión), puedo construir números con, por ejemplo, 18 divisores, de estas formas:  , $p^5\cdot q^2$,
, $p^5\cdot q^2$,  . ¿Cuál es el número más pequeño que tiene 18 divisores?
. ¿Cuál es el número más pequeño que tiene 18 divisores?